빅 엔디안(Big Endian)과 리틀 엔디안(Little Endian)을 이해해보자
들어가며
네트워크 프로그래밍을 하다보면 Ip와 Port를 당연하게 접하게 된다. 컴퓨터 간 Ip 혼동을 없애기 위해 같은 방법으로 데이터를 저장하고, 해석해야한다. 그것을 위해선 빅 엔디안과 리틀 엔디안에 대해 알고 있어야한다.
빅 엔디안 리틀 엔디안??
빅 엔디안과 리틀 엔디안은 CPU가 데이터를 저장하는 방법이다. 말보다는 예시로 이해해보자.
0x12345678라는 정보를 저장한다고 가정해보자.
빅 엔디안의 저장 방식

빅 엔디안은 최상위 바이트(0x12가 저장되어 있는 곳)이 가장 작은(가장 먼저 오는) 호(0x20호)에 저장된다.
하지만 리틀 엔디안은 이와 반대의 방식으로 저장한다.
리틀 엔디안의 저장 방식

리틀 엔디안의 경우는 가장 최상위 비트가 가장 작은 호(0x20호)에 저장된다.
이 처럼 CPU마다 데이터를 저장하는 방법이 다르다. 이로 인해 네트워크 통신에서 문제가 발생할 수 있다.
저장방법으로 인해 생기는 문제
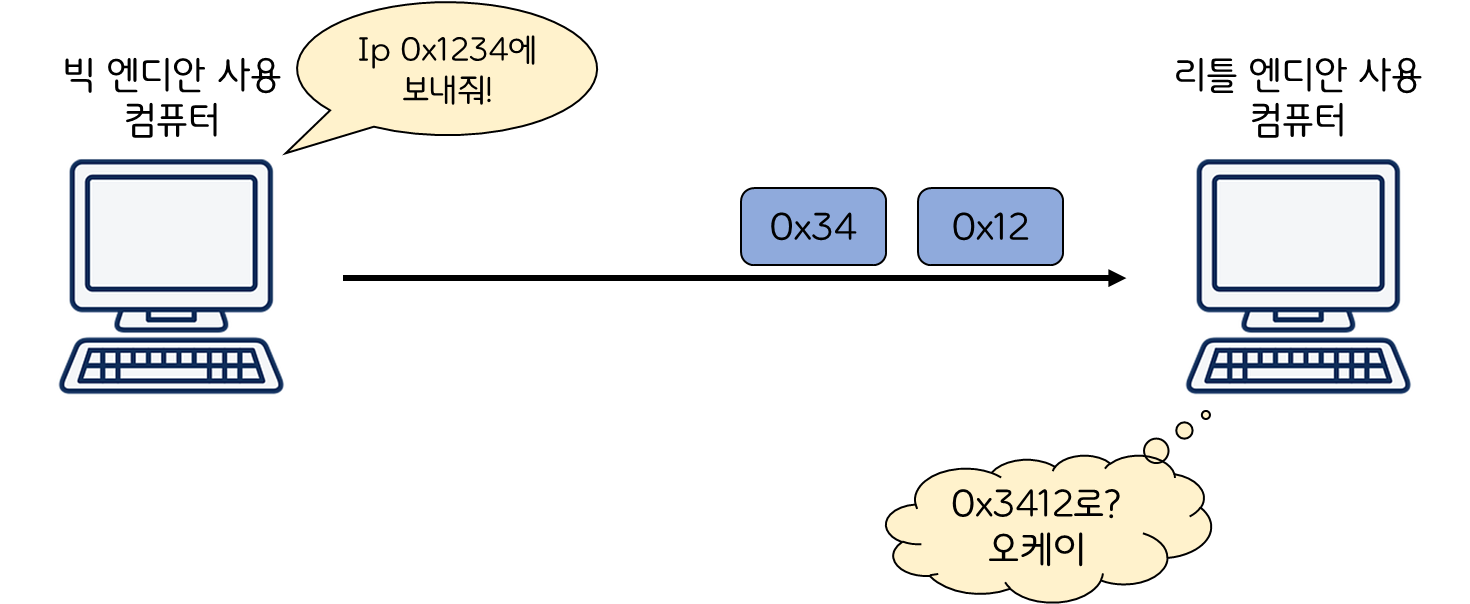
빅 엔디안 시스템 컴퓨터에선 0x1234라는 ip주소를 보냈지만, 그 정보를 받은 컴퓨터는 리틀 엔디안을 사용하고있었기 때문에 0x3412로 정보를 이해하는 상황이 발생해버린 것이다.
그럼 어떡하지?
이런 사태를 방지하기위해 네트워크를 통해 데이터를 전달할 땐 빅 엔디안으로 통일하여 통신하기로 약속했다. 그래서 이를 네트워크 바이트 순서(Network Byte Order)라고한다.
바이트 순서를 변환하는 방법
C++에선 어떻게 바이트 순서를 변환할까? 이것을 돕기 위해 함수가 준비 되어있다.
unsigned short htons(unsigned short);
unsigned short ntohs(unsigned short);
unsigned long htonl(unsigned long);
unsigned long ntohl(unsigned long);이름을 통해 이 함수가 무슨 일을 하는지 짐작할 수 있다.
h는 host로 호스트를 의미하고, n은 network를 의미한다. 또한 s는 short, l은 long을 의미해 어떤 자료형을 변환하는 지 알려주는 것이다. 그럼 htons는 "short형 데이터를 host바이트 방식에서 network방식(빅 엔디안)으로 바꿔줘" 라고 해석할 수 있다.
마무리
이런 의문을 가질 수 있다.
"그럼 제 컴퓨터는 빅 엔디안 방식이니 변환을 안해줘도 괜찮지 않을까?"
틀린 말은 아니지만 리틀 엔디안, 빅 엔디안 상관없이 동일하게 동작하는 코드를 작성하는 것이 좋다.